준지도학습 - 셀프 트레이닝(Self-Training)
by JINKOOK KIM
이 포스팅은 고려대학교 강필성 교수님의 Business Analytics 수업을 바탕으로 작성되었습니다
셀프 트레이닝(Self Training)
준지도학습(semi-supervised learning)
머신러닝에서는 일반적으로 지도학습(supervised learning)과 비지도학습(supervised learning)이 널리 알려져 있습니다.
지도학습(supervised learning)은 데이터의 정답이라고 할 수 있는 레이블(label)이 있는 데이터를 이용해 모델을 학습시키는 것을 의미하고, 비지도학습(usupervised learning)은 레이블이 없는 데이터를 활용하는 모델을 학습시키는 것을 의미합니다.
이때 우리가 레이블이 있는 데이터와 없는 데이터 모두를 가지고 있다면 어떻게 데이터를 낭비하지않고 모두 활용 할 수 있을까요?
그 방법 중 하나가 준지도학습(semi-supervised learning)입니다. 준지도학습은 레이블이 있는 데이터와 레이블이 없는 데이터 모두를 활용해서 모델을 생성해냅니다.
이번 포스팅에서는 준지도학습 중 가장 간단한 모델인 셀프 트레이닝(Self Training)에 대해 다뤄보도록 하겠습니다.
셀프 트레이닝(Self Training)
셀프 트레이닝을 이해하기위해 예시를 들어서 생각해 보겠습니다.
어떤 학생이 시험준비를 하려고 문제집을 풀고있는데 정답지의 일부분이 없어져버렸다고 합시다.
100문제 중 70문제에 대한 정답지가 없어졌다고 할 때, 이 학생은 답이 있는 30문제라도 우선 열심히 공부한 후 나머지 70문제를 풀기 시작합니다. 30문제를 제대로 공부한 학생은 정답지가 없어진 70문제 중 10문제 정도는 ‘내가 다른건 몰라도 이건 확실히 맞출 것 같다’라는 마음으로 이 문제들에 대해서 제가 푼 답을 답지로 만들어버립니다! 이렇게 해버리면 70문제에 대한 답이 있는 셈이겠죠? (물론 정답을 다 제대로 맞췄다고 보장할 수는 없습니다).
이러한 식으로 계속해서 정답지가 없는 문제들에 대해 스스로의 답을 정답이라고 믿으며 정답지를 만들고 공부를 하고 정답지를 만들고 공부를 하는 과정을 계속해 나갑니다. 이 학생은 30개의 문제만을 가지고 공부한 학생보다는 더 많은 문제를 통해 공부를 했기 때문에 성적이 더 잘 나올 가능성이 높을 것입니다.
(물론 틀린 정답지를 만들고 틀린 공부를 할 가능성도 더 높습니다만 공부량이 훨씬 많습니다)
위의 예시에서 공부 = 모델 학습/ 정답지 = 데이터의 레이블 이라고 생각하면 셀프 트레이닝의 개념을 이해했다고 생각할 수 있습니다.
이처럼 레이블이 있는 데이터를 통해 모델을 학습하고, 레이블이 없는 데이터에 레이블을 달아주면서 학습을 계속하는 방식이 바로 셀프 트레이닝 입니다.
셀프 트레이닝의 개념을 이해했으니 보다 구체적인 흐름을 살펴보도록 하겠습니다.
 출처: 고려대학교 강필성 교수님 강의자료
출처: 고려대학교 강필성 교수님 강의자료
위 사진에서 Xl 은 레이블이 있는 레이블을 제외한 데이터 그리고 yl은 그 데이터의 레이블 입니다.
Xu는 레이블이 없는 레이블을 제외한 데이터 입니다.
우선, 어떤 모델이 높은 정확도로 예측한 값은 맞았다고 해주자는 가정을 해야 합니다.
그래야 우리가 레이블이 없는 데이터에 레이블을 달아주는 행위에 정당성이 생기기 때문입니다.
앞서 예시에서 말씀드렸듯이 높은 정확도라고 해서 항상 정확히 맞는다는 보장은 없습니다.
하지만 조금이라도 데이터를 더 활용할 수 있다면 높은 가능성을 가지고 정답을 맞추는 모델을 믿어주는 것도 방법 중 하나이겠지요.
이제 Xl과 yl을 가지고 모델 학습을 시작합니다.
앞선 예시에서 학생이 30문제를 가지고 공부를 하는 부분입니다.
모델을 학습 한 후 모델을 이용해 Xu데이터 중 일부 데이터의 레이블 값을 예측 값으로 대체합니다. 예시의 학생이 정답지를 만들어 나가는 과정이지요. 그리고는 이 과정을 계속해서 반복합니다.
이때 Xu중 어떠한 일부의 데이터에 대해 레이블 값을 예측 값으로 대체하는지에 따라 다른 결과가 나올 수 있겠습니다.
위 자료에서는 3가지 방법으로 나누어 놓았습니다.
- 예시의 학생과 마찬가지로 높게 확신하는 몇 개의 데이터에 대해서만 레이블을 달아주는 경우
- Xu 데이터에 대해 레이블을 한번에 달아주는 경우
- 모든 Xu 데이터에 대해 레이블을 달아주지만 모델이 어느 정도로 확신하는지에 따라 레이블을 달 때 가중치를 주는 경우
그리고 위에 나와있지는 않지만 - Xu 데이터의 일정 비율을 랜덤으로 라벨링 하는 경우(이 방법을 통해서 실험을 진행하였습니다)
직관적으로 생각해 보았을 때에는 2번의 경우가 가장 좋지 않은 성능을 보여줄 것으로 생각이 되고 1번은 점차 수렴해 나가며 합리적인 모델을 도출해 낼 수 있을 것 같아 보이며, 3번은 loss를 계산 할 때 신뢰도가 낮게 레이블이 달린 데이터에 대해 학습을 덜 하게 되므로 또한 합리적으로 보입니다. 4번은 랜덤샘플링을 통해 진행되는 만큼 가장 성능이 좋지는 않겠지만, 모델마다 높은 정확도를 보이는 데이터셋이 다를 수 있는데 이에 따라 생기는 편향성에 가장 덜 영향을 받을 것으로 보입니다. 앞서 말한 셀프 트레이닝은 구조를 생각해보면 학습 모델로 많은 종류의 지도학습 모델이 활용 가능하다는 걸 알 수 있습니다.
실험 및 결과
저는 셀프 트레이닝을 공부하면서 아래와 같은 궁금증이 생겼고 이에 대한 실험을 해보고 싶었습니다.
-
Q1. 우리가 생각한 대로 레이블이 있는 데이터와 없는 데이터가 섞여 있을 경우 셀프 트레이닝을 활용하여 모든 데이터를 활용한 경우가 그렇지 않은 경우보다 실제로 성능이 더 높게 나올까요?
-
Q2. labeled/unlabeled data의 비율에 따라 어떤 결과의 차이가 있을까요?
-이에 대한 실험은 잘 정리해놓은 곳이 있습니다. 이곳을 참고해주세요
labeled 데이터가 초기에 많을 수록 대체적으로 더 정확한 분류를 해내는 모습을 살펴 볼 수 있습니다
따라서, 첫 번째 질문에 대한 답을 얻기 위한 실험을 살펴보도록 하겠습니다
-
데이터 설정:
실험을 계획 할 때 데이터에 따른 차이를 알고 싶은 것은 아니지만 데이터셋에 따라 결과가 다를 수 있기 때문에 3가지 데이터셋에 대해 결과를 살펴보고자 하였습니다. 데이터셋 마다 일정 비율(학습 데이터셋 중 80%)을 랜덤으로 지우는 방법을 통해 레이블이 없는 데이터를 강제로 생성해냈고 이에 대한 데이터의 개수 및 비율은 다음과 같습니다.
(데이터는 uci 에서 제공하는 데이터셋 사이트에서 받아 이용하였습니다.데이터셋 이름 IRIS data Wine Quality Wheat Seeds Dataset 레이블 없는 학습데이터 수(비율) 108 (72%) 3526 (72%) 150 (72%) 레이블 있는 학습 데이터 수(비율) 27 (18%) 881 (18%) 37 (18%) 테스트 데이터 수(비율) 15 (10%) 490 (10%) 21 (10%) 총 합 150 (100%) 4898 (100%) 209 (100%)
- 실험 아이디어:
위의 데이터에서 우리가 생각한 대로 레이블이 있는 데이터와 없는 데이터가 섞여 있을 때 셀프 트레이닝을 활용하여 모든 데이터를 활용한 경우가 그렇지 않은 경우보다 실제로 성능이 더 높게 나올까요?
이에 대한 답을 얻기위해 레이블이 있는 학습 데이터만을 학습한 모델과 레이블이 없는 학습데이터를 일정 비율만큼 셀프 트레이닝 하여 학습한 모델을 Test 셋 데이터를 통해서 성능을 비교해 보고자 합니다. -
실험 결과 표:
블로그에 넣기에 표가 방대하여 엑셀 이미지를 첨부하였습니다. 아래 표를 보시면 각 데이터 셋 별로 여러 모델의 Accuracy를 비교한 결과를 보실 수 있습니다. 이때 Unlabeled data를 얼만큼 셀프 트레이닝으로 추가 학습 시켰는지 0.0/0.2/0.4/0.6/0.8/1.0 비율을 통해서 나타내었습니다. Max 값은 각 행/열 에서 가장 높은 값을 보여주며 그때 사용된 모델/그리고 Unlabeled data의 비율이 무엇인지 나타내었습니다.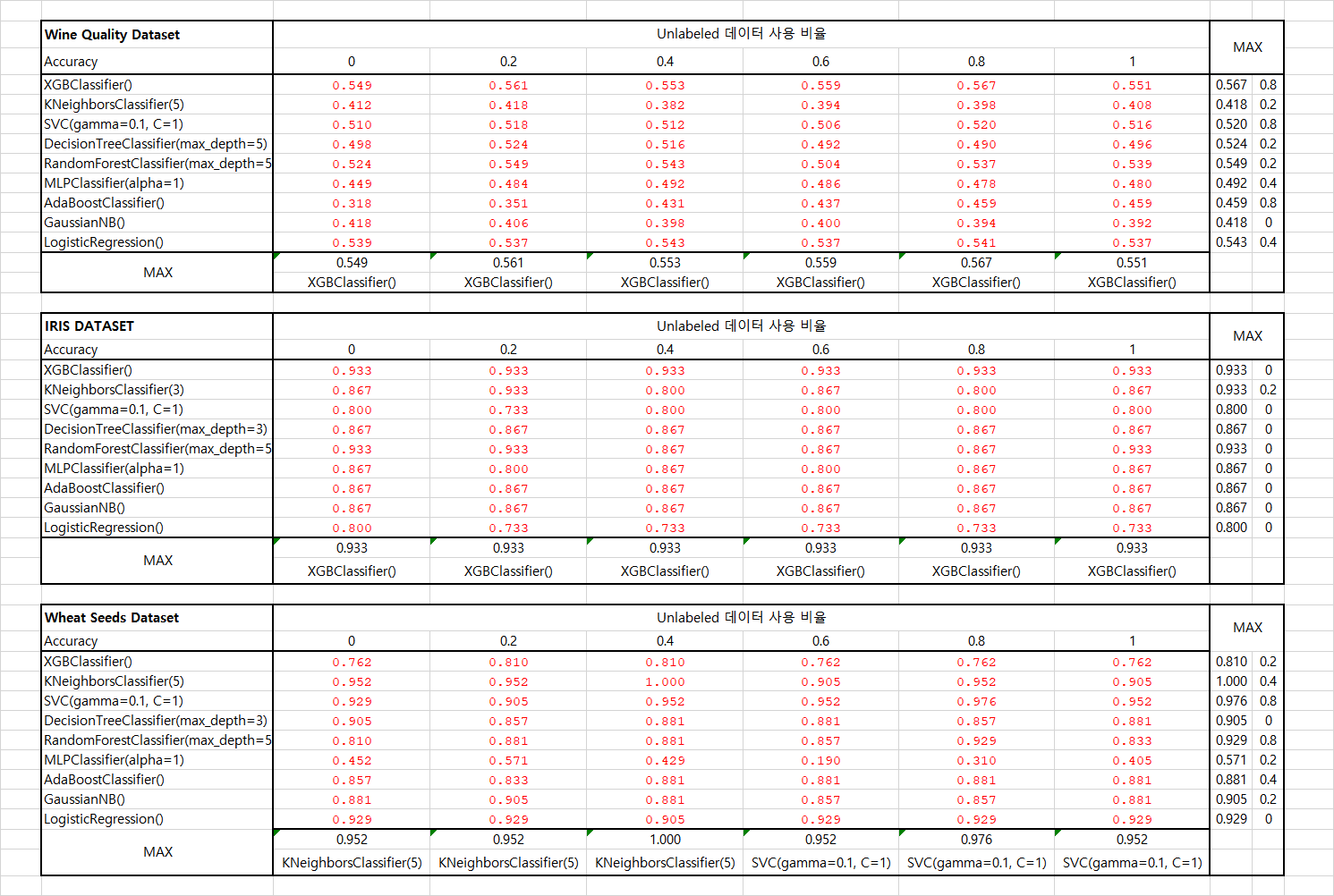
- 결과 해석:
셀프 트레이닝 기법이 정확도를 소폭 상승시켜주는 모델도 있지만 20%의 데이터만을 이용해 학습한 결과보다 크게 나아지는 모습을 보여줬다고 하기는 애매했습니다. 전반적으로 소폭의 성능향상을 기대할 수 있으나, 오히려 떨어지는 경우도 있어서 반드시 실험을 해보고 활용해야 할 듯 합니다. IRIS 데이터의 경우 training data가 워낙 작다보니 편향이 심한 모델을 통해서 셀프 트레이닝을 했을 때 오히려 결과가 나빠지는 모습을 볼 수 있었습니다.
KNN과 Decision Tree 처럼 초반의 갈림이 후반에 큰 영향을 주는 모델의 경우 성능이 오히려 악화되는 모습도 볼 수 있었습니다.
가장 단순한 아이디어에서 시작한 기법인 만큼 큰 효과를 보여주지는 못하였지만, 이를 토대로 발전한 다른 semi-supervised learning 기법들은 unlabeled data를 활용하여 성능 개선에 큰 도움을 줄 수 있다고 합니다.
준 지도 학습 방법 중 하나인 셀프 트레이닝의 개념에 대해 살펴보고 Unlabeled data의 비율과 모델에 따라 성능이 어떻게 변하는지 살펴보았습니다.저와 같은 실험을 해보고싶으신 분을 위해서 아래에 제가 사용한 코드를 작성해놓았습니다.
작성된 코드는 Python Anaconda 3.6 버전에서 2018년 12월 현 시점 가장 최신 버전의 sklearn, numpy, pandas 패키지를 이용하였습니다.
직접 작성한 코드라 이해가 잘 안되는 부분이 있을 수 있습니다.
궁금하신점은 wlsrnr1218@naver.com 으로 메일주시면 답변드리도록 하겠습니다. :)
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
# iris = load_iris()
from pandas import *
from sklearn.model_selection import train_test_split
dat = read_csv('winequality.csv', sep=';')
# dat = read_csv('Wheat Seeds Dataset.csv', sep=' ')
# dat = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
# columns= iris['feature_names'] + ['target'])
x_train, x_test, y_train, y_test = train_test_split(dat.iloc[:,:-1],
dat.iloc[:,-1],
test_size = 0.2,
random_state = 1218, shuffle = True
)
label_x_train, unlabel_x_train, label_y_train, unlabel_y_train = train_test_split(
x_train,
y_train,
test_size = 0.8,
random_state = 1218, shuffle = True)
from sklearn.utils import shuffle
from sklearn.base import BaseEstimator, RegressorMixin
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_moons, make_circles, make_classification
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
import xgboost as xgb
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_moons, make_circles, make_classification
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
class PseudoLabeler(BaseEstimator, RegressorMixin):
def __init__(self, model, my_Xu, features, target, sample_rate=0.2, seed=42):
self.sample_rate = sample_rate
self.seed = seed
self.model = model
self.model.seed = seed
self.my_Xu = my_Xu
self.features = features
self.target = target
def get_params(self, deep=True):
return {
"sample_rate": self.sample_rate,
"seed": self.seed,
"model": self.model,
"my_Xu": self.my_Xu,
"features": self.features,
"target": self.target
}
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
def fit(self, X, y):
if self.sample_rate > 0.0:
augemented_train = self.__create_augmented_train(X, y)
self.model.fit(
augemented_train[self.features],
augemented_train[self.target]
)
else:
self.model.fit(X, y)
return self
def __create_augmented_train(self, X, y):
num_of_samples = int(len(self.my_Xu) * self.sample_rate)
# 모델을 학습하고 셀프 트레이닝으로 라벨 구하기
self.model.fit(X, y)
pseudo_labels = self.model.predict(self.my_Xu[self.features])
# test 셋에 셀프트레이닝으로 라벨링 하기
augmented_my_Xu = self.my_Xu.copy(deep=True)
augmented_my_Xu[self.target] = pseudo_labels
# test 셋에 셀프트레이닝으로 라벨링한거의 일부를 빼다가 train 셋에 추가하기
sampled_my_Xu = augmented_my_Xu.sample(n=num_of_samples)
temp_train = pd.concat([X, y], axis=1)
augemented_train = pd.concat([sampled_my_Xu, temp_train])
return shuffle(augemented_train)
def predict(self, X):
return self.model.predict(X)
def get_model_name(self):
return self.model.__class__.__name__
features = x_train.columns
target = dat.columns[-1]
#데이터 전처리
# label_x_train, unlabel_x_train, label_y_train, unlabel_y_train
self_data = pd.concat([unlabel_x_train, unlabel_y_train], axis=1)
classifiers = [
xgb.XGBClassifier(),
KNeighborsClassifier(5),
SVC(gamma=0.1, C=1),
DecisionTreeClassifier(max_depth=3),
RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1),
MLPClassifier(alpha=1),
AdaBoostClassifier(),
GaussianNB(),
LogisticRegression()]
# 모델 학습 및 예측
my_classifier = LogisticRegression()
self_model = PseudoLabeler(model = my_classifier,
my_Xu = self_data, #셀프트레이닝으로 라벨 달아갈 데이터
features= features,
target = target,
sample_rate= 0.99 ,
seed=4
)
self_model.fit(label_x_train, label_y_train)
print(accuracy_score(self_model.predict(x_test), y_test))
just_model = my_classifier
just_model.fit(label_x_train, label_y_train)
print(accuracy_score(just_model.predict(x_test), y_test))
Subscribe via RSS